
The basics of SEO for developers
SEO is all about showing up on the first page of Google for relevant keywords. If done well, this can be a major source of traffic and revenue for your client.
To reach that top spot, a website needs to have three things - the three pillars of SEO:
- Great content that answers the search intent of searchers
- High authority, which is mostly gained by getting a lot of links to the site
- A solid technical foundation that allows Google to crawl, index, and understand the website.
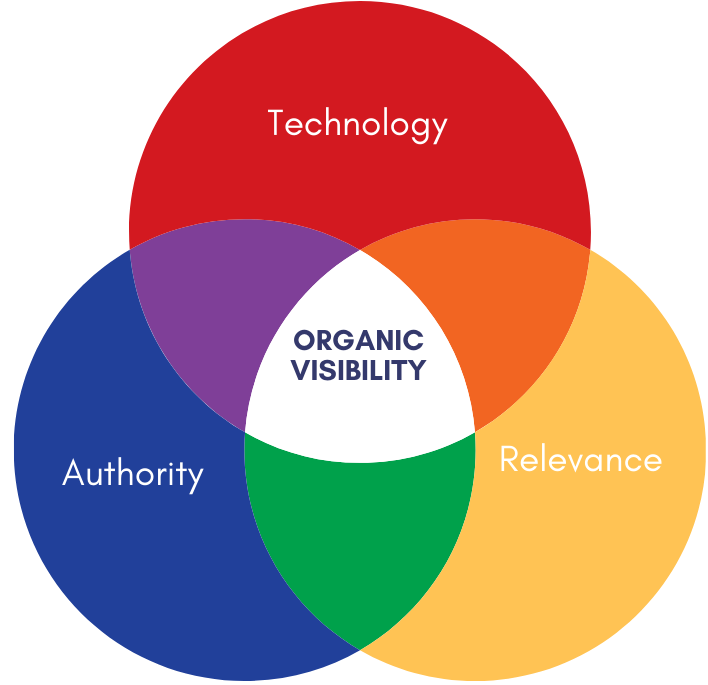
As a developer, you're in control of the last one: the technical foundation. Without that, your colleagues can create the best content and get great links to the site, but they'll still have a hard time getting the site to rank. You're indispensable for SEO success - no pressure!
This article gives you the basic SEO knowledge you need to optimize that technical foundation. Without the fluff.
Help Google crawl the site
Google's crawler is called the Googlebot. It visits a web page, finds links on that page to other pages, and crawls those pages too. It stores those pages in its index and shows them in the search results if relevant.
The first step is to make sure Google can crawl your website. Here are a few things you can do as a developer to improve crawlability.
![]()
Add a sitemap.xml
A sitemap is an XML file that includes all pages of a website. SEO specialists can submit a sitemap to Google to speed up indexing and monitor how many pages are indexed. You'll make your SEO colleagues very happy by creating an XML sitemap. Ideally, one that is regularly updated so it always has the latest content. This is a great first step to make sure Google can find all the pages on the site.
For very large sites it can be nice to split it up in smaller subsitemaps, but technically a sitemap can hold up to 50,000 URLs.
Add a robots.txt file
A robots.txt file in the root of a site can be used to instruct search engines to skip certain folders or pages when crawling the site. It can also be used to block search engines from indexing a staging or acceptance website.
If you don't have a robots.txt file in the root, search engines will crawl all the pages they can find. So unless you explicitly block something, the site can be crawled and indexed.
Getting the site indexed
After crawling comes indexing. Unless a search engine includes specific instructions to not index a page, it will include it in the index.
In some cases, it may be useful to exclude certain pages from the search engine's index. An account page, a wishlist page, etc, are often excluded. There are 2 ways of excluding (no-indexing) these pages:
Using a meta tag:
<meta name="robots" content="noindex">
Using an HTTP header:
X-Robots-Tag: noindex
Adding these instructions to a page will remove it from the search engine, so be very careful, and only use it if there's a good reason why you don't want to see that page in Google.
Canonical URLs
As a developer, you have some control over which pages can be indexed. By adding a so-called canonical tag to the head of a page, you specify which URL search engines should index.
It looks like this:
<link rel="canonical" href="https://www.mywinestore.com/red-wine/creation-merlot">
Canonical URLs are especially helpful when multiple variants of a page exist. Some examples in which canonical URLs are helpful:
- Pagination (https://www.example.com/blog/page-1, or https://www.example.com/blog?page=1)
- Product filters (https://www.example.com/products?color=red&size=42)
- Blogs in multiple categories (www.example.com/blog/about-us/our-story and www.example.com/blog/stories/our-story, if both are the same blog post)
- Very similar pages, for instance, two color variants of the same product
In each of these cases, you don't want all variants to be indexed. The canonical tag allows you to indicate the preferred page, and normally Google follows that recommendation.
General rule: always include a clean, self-referencing canonical without URL parameters on every page. This way you avoid duplicate pages being indexed. That canonical URL should not be redirected and be indexable.
Optimize Internal linking
Internal links are used by Google to determine the relative importance of a page. A page with many internal links pointing to it will be seen as more relevant than one without internal links.

HTML links that work without javascript
Google's initial visit is by a bot that does not render javascript. It only considers the raw HTML. To help Google follow all internal links, make sure the href-part of a link is an actual URL.
Some examples:
- <a href="https://www.example.com/about-us">About us</a> this is excellent
- <a href="/about-us">About us</a> this is great too
- <a href="javascript: window.location='/about-us'">About us</a> this is not good. Google won't follow this link
- <a href="javascript:goToPage(7331)">About us</a> please stop this madness
Pro-tip: always use a proper link that works without javascript. If you're using Ajax, use a regular href as a fallback:
<a href="/about-us" onClick="visitPage(‘about-us')">About us</a>
Anchor links
With the rise of Single Page Applications, anchor links (#about-us) have become more popular. Keep in mind that Google doesn't follow anchor links, and does not include them in the index. It considers both these links as the same page:
- https://www.example.com/about-us
- https://www.example.com/about-us#about
The latter won't get indexed separately.
Create a good URL structure
A simple, clean URL structure helps Google better crawl and understand your website. Some general rules:
- The fewer directories, the more relevant a page normally is.
- However, having no directories at all means everything is equally important, so nothing is important
- Including relevant keywords in the URL can help to rank for that keyword
- Google favors hyphens over underscores as a word separator
- Hashes are ignored by search engines
- Try to avoid using URL parameters for navigation purposes
Some good examples:
- https://www.example.com/category/product-name
- https://www.example.com/blog/my-first-post
Some bad examples:
- https://www.example.com/page/1337 (no relevant keywords)
- https://www.example.com?page=contact (using URL parameters for navigation)
- https://www.example.com/shop/category/product-collection/product (to deep)
Using metadata for SEO
Your SEO colleagues use metadata such as the page title and meta description to help Google understand what a page is about, and increase clicks to the site. Having a relevant page title and meta description increases the chance of showing up in Google for the right keywords. Since both are often shown on the search results page, they are like a pick-up line for the site: they need to seduce people to click on that particular result.

Page title
A page title should be a short title of the page and often also includes the brand name, ideally between 50 and 70 characters. It looks something like this and is placed in the head of the HTML:
<title>SEO for developers - SiteGuru</title>
Meta descriptions
The meta description is often (although not always) shown under the title in the search results. It should be between 120 to 170 characters, and provide a good description of what the user can find on the page, without spilling the beans - we still want the searcher to click on it.
Meta description & page title best practices
Most SEOs will be very happy if your application does two things regarding page titles and meta descriptions:
- Give content managers control over the title and meta description, for instance by adding fields where they can provide a title and meta description.
- If nothing has been provided, set a relevant default value. This is especially relevant for big websites when content editors don't always have the time to set up custom titles and meta descriptions. Using a format like Product name - Website name for the title, and using the first 150 characters of a product description or blog post can be a good alternative.
Bonus: OG tags
Although not specific to SEO, OpenGraph tags can be valuable too. These tags are used to generate previews of a website on social media. Supplying a relevant title, description and image can help bring more visitors from social channels
Some examples are the og:type, og:title, og:image and og:description tags. It's a good idea to use the page title as the OG title, and the meta description as the OG description:
<meta property="og:type" content="article" /
<meta property="og:title" content="My amazing blog post" />
<meta property="og:image" content="http://assets.website.com/high-quality-image.jpeg" />
<meta property="og:url" content="http://www.mywebsite.com/contact.html" />
<meta property="og:description" content="In this blog post, I tell you all about my life. Special attention for my cat, who I really love." />
Add Structured data
Structured Data is a way to tell Google and other search engines what the different elements on your page mean. It takes normal HTML and turns it into meaningful entities that search engines understand.
While having Structured Data is not a direct ranking factor, using it has two major benefits for SEO:
- It helps search engines understand the meaning of content on a webpage
- It helps increase the visibility of a page in the search results
Here's an example of how structured data in a recipe is used to enhance the search result:
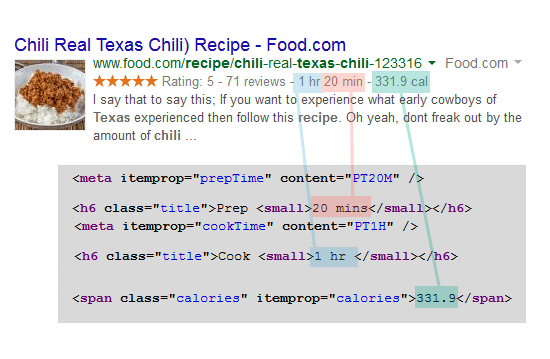
Some types of content for which Structured Data is especially valuable:
- Products (including price and availability)
- Local businesses, such as stores
- Blogposts
- Organizations, such as the company's details
- Events
There's more, but these are usually great candidates for adding Structured Data. You can find all the exact definitions on Schema.org.
The great thing about Structured Data is that often the data itself is already available in the system: a product already has a price, title, and availability. All that's needed is to add the right attributes to the existing code. Here's an example of a product with Structured Data:
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "Product",
"name": "Nike Running Shoe",
"image": "/running-shoe.png",
"offers": {
"@type": "Offer",
"availability": "http://schema.org/InStock",
"price": "129.00",
"priceCurrency": "USD"
}
}
</script>
Structured Data can be added via JSON-LD (a JSON object that holds all the data), or via Microdata (adding attributes to the existing HTML). Both work equally fine, so whichever way is easiest to implement works.
After implementing Structured Data, make sure you test it in Google's Rich Results Test. By copying the code into the testing tool, you can also test code that's not live yet.
Page speed and SEO
Page speed is a big topic in SEO these days, because Google has stated its importance, and said it might be included as a ranking factor. There's a good chance this has caused some SEOs to come to your desk asking for better page performance.
That's not a bad idea, and not just for rankings. Faster pages also provide a better user experience and convert better.

Step one is to use Google Lighthouse or Google Pagespeed Insights to see how the site is currently performing. You'll receive a score between 0 and 100. Anything under 50 is really bad, but we suggest trying to get that score over 70. Obtaining a higher score often requires much more effort, without improving the user experience significantly.
Google's tools will also give you some hints to improve your page speed. Some of these are really easy to implement, others are a lot harder.
Here are some relatively easy fixes (of course, depending on your technical setup) that can boost the score quickly without too much effort. A great way to impress your SEO colleagues:
- Enable text compression: reduce the size of the data by using Gzip or Brotli (more)
- Leverage browser caching: using the right expiry settings can greatly reduce loading times without much effort (more)
- Preloading and pre-fetching assets: speed up the connection to external assets with just a few lines of code.
Another recurring theme in page speed discussions is images: they can greatly increase loading times, but if used correctly, this doesn't have to be the case. Using the right size, format, and caching goes a long way. More on images and page speed
Some other recommendations often take more time to implement, so it's up to you to decide whether it's worth pursuing these:
- Remove render-blocking resources: great if you can fix this, but often requires inlining CSS or Javascript, which makes it complex
- Removing unneeded CSS and Javascript: depending on the file size, you can try to remove specific pieces of JS and CSS that are only used on some pages. However, deciding per page which JS and CSS resources are needed is quite complex.
If you want to know more about how page speed and Core Web Vitals are measured, we have a complete guide on page speed.
Redirects and response codes
Another favorite topic of SEOs: redirects. Especially relevant during migrations, or whenever URLs change.
If for some reason a URL changes, it's a good idea to redirect the old URL to the new one. For two reasons:
- Any visitor using the old URL will end up on the right page, instead of on a 404.
- Any 'SEO value' of the old URL is - for the most part - carried over to the new URL.
There are 2 types of redirects, identified by their HTTP status code:
- A 301 redirect, which is used for pages that are moved permanently. Google will eventually remove the old URL, and use the new one instead
- A 302 redirect, used for temporary moves. Google will not carry over much of the SEO value, and updating pages in its index usually takes longer.
If a URL move is definitive, always use a 301 redirect - moved permanently.
Every redirect should go to a page that returns a status code 200 - OK. Try to avoid redirect hops, going from page A, to B to C. Especially avoid redirect loops, going from page A, to B, back to A.
More about HTTP status codes
More about redirects and SEO
Page structure
You know how headings (h1 to h6) can be used to structure a page. Google also pays attention to this and considers a H1 to be a very relevant piece of text on the page.

SEOs would like to have some control over what is the H1 on the page, as well as the other headings of the page. Some basic rules:
- Every page should have only one H1
- Normally there's no need to go beyond an H4
Images and Alt texts
We've briefly discussed images as part of the page speed section, but there's another requirement: alt texts.

Alt texts are used by screen readers, but also help Google understand what the image is about. Given the increasing importance of image search, SEOs will ask you to give them control over image alt texts. This lets them set relevant alt texts, boosting performance in image search.
Prevent duplicate content
Duplicate content is a popular topic in the SEO world, and it's often misunderstood. Duplicate content refers to two identical pages.
First of all: there's no such thing as a duplicate content penalty. That being said, it is a good idea to prevent duplicate content. Not because of penalties, but because those similar pages might compete with each other in search results.
The canonical tags we discussed earlier can help prevent duplicate content in situations like pagination, or filtering. By setting a correct canonical URL, Google will only index that canonical URL and ignore the other ones.

There are some other ways you as a developer can help prevent duplicate content:
- HTTPS: pages that work both with and without https can be seen as duplicates. Redirect to the https variant to avoid this (and also avoid security risks)
- WWW: pages that work both with and without www can also be seen as duplicates. Always redirect visitors to the www variant of the domain. Or the one without, but make sure that the URL with and without www don't work both.
- Trailing slash: some pages work both with and without a trailing slash. Always redirect to one of the 2 variants. Which one, doesn't matter.
It's a good idea to do these redirects early on in the stack. Also, try to combine the redirects, to avoid the following redirect chain:
- http://example.com/contact/
- https://example.com/contact/
- https://www.example.com/contact/
- https://www.example.com/contact
That's 3 redirects in a row!
If you're using an Apache server, the following lines always redirect visitors to the URL with https, www and without a trailing slash:
RewriteEngine on
# Remove trailing slash
RewriteCond %{REQUEST_URI} /(.+)/$
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule ^ https://www.example.com/%1 [R=301,L]
# Force HTTPS and WWW
RewriteCond %{HTTP_HOST} !^www\.(.*)$ [OR,NC]
RewriteCond %{https} off
RewriteRule ^(.*)$ https://www.example.com/$1 [R=301,L
Learn more about duplicate content
Avoid client-side rendering
There's one important topic we still need to discuss: client-side rendering.
With the rise of front-end frameworks like Vue, Angular and React, client-side rendering has become very popular. If done wrong, this can have a detrimental effect on SEO.
As we've seen earlier, Google initially visits a website without rendering javascript. If your website is basically an empty shell, and all content is added in later using javascript, Google will never see that content. Also, it won't follow any links, and it might not even catch your meta data and page title. Ranking these pages will take a lot more time, if they ever rank at all.
The good news is that all the front-end frameworks have recently added more server-side rendering capabilities. Use this whenever possible: your SEO colleagues will thank you.
Keep learning
Congrats for making it up to here. You've leveled up your SEO knowledge, and we hope this helps you built websites that do better in organic performance. Maybe you've also discovered that SEO can be fun. If so, head over to the SEO Academy to learn more!
If you want to learn more about SEO as a developer, we recommend signing up for the SEO for Devs email course by Monica Lent. It's a 2-week course that focuses on growing your site through SEO, even if you're not a marketer.
