
A robots meta tag is a small piece of HTML that tells search engines how to index and display a page. The most common one, the noindex tag, keeps a page out of search results. There are pages you will not want Google to index, and robots meta directives are how you say so.
This guide covers when to use robots meta tags, how they differ from the robots.txt file, and the directives you are most likely to need.
What Are Robots Meta Tags?
Unlike the robots.txt file, which tells robots how to crawl your website, the robots meta tags specify how your pages are indexed and displayed on the SERPs.
They’re pieces of HTML inserted in your page’s header (<head>). In practice, it’s a piece of code that looks something like this (if we wanted to tell Google not to index this page):
<meta name="robots" content="noindex">
Depending on the directive you’d like to use, you’d simply replace the “noindex” value with your directive or add more directives by separating them with commas:
<meta name="robots" content="noindex,nofollow">
What’s the Difference Between the robots.txt File and Robots Meta Tags?
In short, if you want to no-index a page or have more granular control over how Google perceives a specific page on your website, use the robots meta tag.
If you want to provide broader directives for a group of pages or your entire website, or stop the bots from crawling them, use the robots.txt file.
When You Should Use the Robots No-Index Meta Tag
<meta name="robots" content="noindex">
Use the robots no-index meta tags if:
- You have pages you don’t want to index. For example, confirmation pages, privacy policy pages, etc.
- You want to protect your back-end, staging, or sensitive content.
- Keep content gated. For example, if some content is only available to your members, special customers, or part of an exclusive offer.
- You want to prevent duplicates. For example, if you have nearly identical product pages that you send ad traffic to, and you don’t want Google to index them or flag one as a duplicate.
To check if a page has been set to noindex, use our Noindex Check Tool.
How to Use Different Robots Meta Tags
In addition to the no-index meta tag, there are plenty of other tags you might need to use. These are the few I see popping up most often:
How to use the Meta Robots “noindex,follow” Tag
<meta name="robots" content="noindex,follow">
If you don’t want search engines to index your page but still want them to follow links on it, you’d use the directive above.
This is a typical use case for replaced pages. For example, out-of-stock product pages that were replaced by a new variant, but their original pages still have valuable internal links.
However, you don’t necessarily need to specify this. Search engines will automatically follow the links on your page (unless you instruct them otherwise).
Meta Robots “noindex,nofollow” and “none” Tags
<meta name="robots" content="noindex,nofollow">
Use this tag if you want to make sure search engines don’t index and don’t follow the links on your page.
It’s used in the same way you’d use the following meta tag:
<meta name="robots" content="none">
Both tags provide the same directive.
Meta Robots “noarchive” Tag Use Cases
<meta name="robots" content="noarchive">
Search engines typically archive and serve cached page versions. Use this directive to ensure your page is not retained in search bots’ archives or cached before display.
For example, you could use this for pages that are often changed.
Skip the Snippet with the “nosnippet” Tag and the “data-nosnippet” Attribute
<meta name="robots" content="nosnippet">
If you don’t want the search engines to display a meta description or a snippet below your page title, use the “nosnippet” directive.
(This is the default when there are indexing errors like “Indexed, though blocked by robots.txt.”)
You can also go more granular by specifying which parts of the content can’t be shown in a snippet with the data-nosnippet attribute.
For example, if you’ve built up a cliffhanger with your page title, you might not want Google to give away your big secret before the searchers click through.
<p>We’ll display this <span data-nosnippet>but we don’t want this content to get displayed in the SERPs</span>.</p>
“Noimageindex” Meta Tag
<meta name="robots" content="noimageindex">
Use the “noimageindex” meta robots tag if you don’t want Google to index the images on your page.
“Notranslate” Meta Tag
<meta name="robots" content="notranslate">
Since Google offers to translate pages from the search results, you can use this directive to ensure it doesn’t provide translations for your page.
What about the X-Robots Tag?
The X-robots tag is used when you want to stop search engines from indexing non-HTML assets like videos, images, and files. You can also use it when you want to add directives in bulk, such as no-indexing an entire folder.
The X-robots tag is in the HTTP Response header of your website.
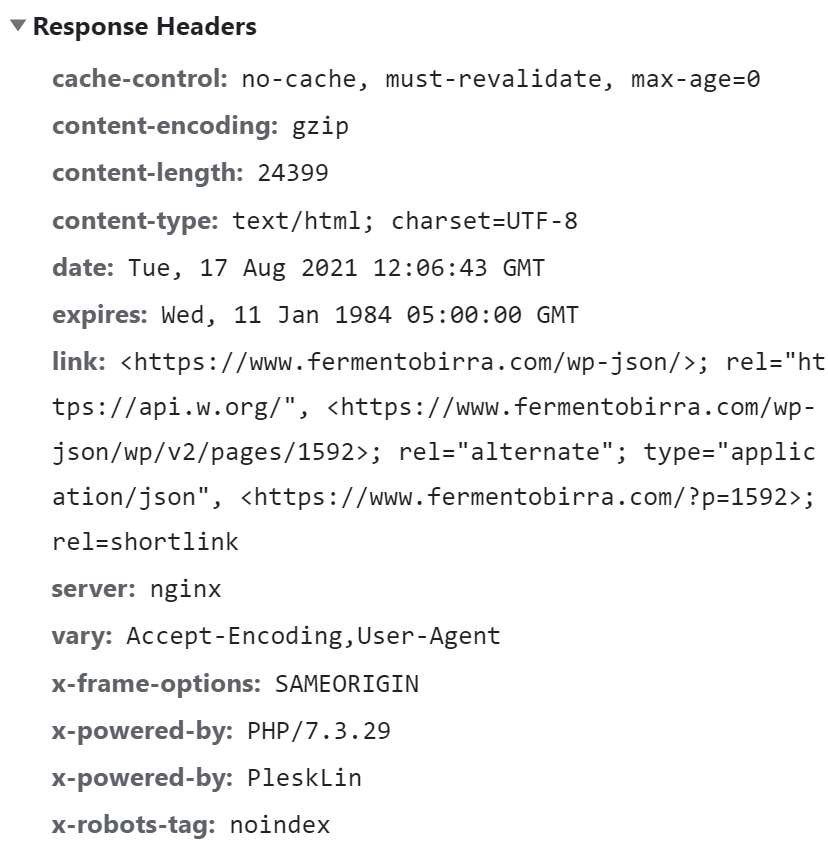
Still, because using the X-robots tag requires touching your website code, make sure you’re familiar with how to implement it on your specific server type or contact a developer.
Small mistakes can affect your entire website, so be careful.
FAQ
1. What happens if there are conflicting directives?
It depends on the search engine. For example, Google will always default to the most restrictive directive, while others may not.
2. Can I use robots.txt and robots meta tags to no-index my page?
No. It can create errors and confusion.
For example, if you disallow a page in the robots.txt file and add the “noindex” tag to it, search bots won’t even spot it.
Similarly, don’t remove the pages from your XML sitemap before the search engines have seen the directive.
3. Can I no-index canonical and translated pages?
If your pages have canonical or hreflang tags, don’t try to no-index them. Alternatively, make sure the right pages have the tags so there’s no confusion.
4. Can I use the no-index tags to prevent paginated pages from being indexed?
You shouldn’t; search engines know to treat paginated pages differently.
Wrapping Up: Differentiating between Robots Meta Tags, robots.txt, and X-Robots
It’s a good thing search engines give us plenty of options to control how they crawl and index our content, but make sure you don’t get confused!
- Use the robots.txt file to control crawling and conserve your crawl budget.
- Use the robots meta tags to control page indexation and other functions related to HTML files.
- Use the X-robots tag to perform actions in bulk or prevent the indexation of non-HTML files.
If you’re new to SEO, take it one step at a time. First, check if your page can be indexed, and then tread lightly. You can even use a weekly SEO audit tool like SiteGuru to ensure your pages are (no)indexed - just the way you want them to be.

