
What is a canonical URL?
Canonical URLs help prevent duplicate content from being indexed. It's a way of telling search engines what is the preferred URL to index.
Canonical URLs are especially helpful when multiple variants of a page exist, and that's more common than you might think.
To better understand how canonicals work, here's an example. Say you run a wine webshop and have various category pages: white wine, red wine, sparkling, etc. Additionally, you have created country-specific pages: French wine, Italian wine, South-African wine, etc.
Your URL structure also reflects this. If we have a red wine from South-Africa, it may be available on 2 URLs:
- https://www.mywinestore.com/red-wine/creation-merlot
- https://www.mywinestore.com/south-africa/creation-merlot
Both URLs show the same wine, and search engines rightly see this as duplicate content. If the first URL is our preferred URL, we add the following canonical:
<link rel="canonical" href="https://www.mywinestore.com/red-wine/creation-merlot">
This way we tell Google to always use that URL. Google normally follows this instruction, so this fixes your duplicate content problem.
When to use canonical URLs?
Pagination
Pagination is used to separate product pages and blog category pages into separate lists.
This creates a lot of different pages, but we don't want page 1,2, 3 to 100 indexed by search engines as different pages.
This is where canonical URLs come in: create a page that has all the posts without pagination (for instance on /all-posts), and set that page as a canonical URL or all paginated pages. Example:

On https://www.example.com/posts?page=1
<link rel="canonical" href="https://www.example.com/all-posts">
Warning: do not set the first paginated page as a canonical URL. This makes it a lot harder to index posts or products that are not on page 1.
Filtering
Product category pages often have filters that are set as URL parameters. As you use the filters on the page, the URL gets updated.
You've seen pages like www.example.com/shirts?color=red&size=medium.
Without using canonical URLs, each of those URL variants can be indexed by Google:
www.example.com/shirts
www.example.com/shirts?color=red&size=medium
www.example.com/shirts?color=red&size=small
www.example.com/shirts?color=green&size=medium
www.example.com/shirts?color=green&size=small
And so on...
You can see the risk: all these URLs can start competing for the same keywords. Again, the fix is simple. Add a canonical URL without any URL parameters, and search engines will only index that one:
<link rel="canonical" href="https://www.example.com/shirts">
Very similar pages
Some websites have pages that are very similar, but with a small difference. A clothing store might sell the same shirt in white, blue, and red, each having its own URL. The same can be done for different flavors, sizes, and so on.

Whether you should canonicalize those pages or not, depends on the search intent. Do you expect searchers to search for specific colors, flavors or sizes? Then every page should be indexed separately, to give searchers what they're looking for. If that's not the case, it's a good idea to canonicalize the pages to one of the variants.
Products or Post in multiple categories
Some content management systems allow you to add posts or products to multiple categories. If that category is also included in the URL, you may end up with exactly the same page on different URLs.
https://www.example.com/category-1/my-first-post
https://www.example.com/category-2/my-first-post
Again, canonicalization helps to fix this. Set up a canonical that points to the most relevant category to avoid duplicate content.
Guest posts
Canonical URLs can point to different domains. That's especially useful if you've written a guest post that's published on your own site, but also on a different publication.
Without canonical URLs, this would be considered duplicate content. Google might assume one of the two articles was copied. By setting a canonical URL that points to your page, you avoid being penalized, and your site gets the SEO value. Of course, this depends on whether the publication allows you to add a canonical URL.
By default: self-referencing canonical
A canonical doesn't have to point to another page when optimizing your URL. A self-referencing canonical is a canonical that points to the page itself.
It is recommended to always add a self-referencing canonical to every page if it doesn't have a canonical pointing somewhere else.
Should I add a self-referencing canonical?
You may think: this page does not use pagination, and I'm not using URL parameters, so do I need a self-referencing canonical?
The answer is yes: even though you may not use URL parameters, external sites may link to that page and add their own parameters. By adding a canonical URL that points to the page itself, you prevent that the URL with parameters gets picked over the original URL.
Common issues with canonical URLs
Search engines follow canonical URLs quite strictly. That means it's a powerful tool, but it also means you need to be careful. There are some common issues that we often see:
Pointing to a non-indexable page
The point of the canonical URL is for that page to be indexed by search engines. If that page has a no-index header or tag, the page will not be indexed, and neither will all pages that have that non-indexable page as a canonical URL.

Therefore, always check if the canonical URL you're using is indexable. SiteGuru's canonical report does this for you.
Redirected canonical
As your site grows and changes, you may redirect pages to different pages. If a redirected page is set as a canonical URL on different pages, that may cause indexation issues. Google tries to use the canonical URL you provide but normally doesn't index redirected pages.

Always use the final URL as a canonical URL, and avoid redirects. SiteGuru's canonical report notifies you when a canonical URL is redirected.
Duplicate canonical
Say you have page 1 set as a canonical URL of page 2. But page 2 also has a canonical URL, page 3. That's not very efficient.

Instead, page 2 should have page 3 as a canonical URL. This increases the chance that search engines interpret your canonicals correctly, and avoids wasting crawl budget.
Using relative URLs
Always use absolute URLs for canonicals. Include the protocol (https://), the full domain name (www.example.com) and the path (/blog/my-blog-post)
Capitalization
Keep in mind that canonical URLs are case sensitive. You can choose to use uppercase or lowercase, as long as you keep it consistent across different pages.
http://www.example.com/blog/Post1 (note the uppercase P)
is a different page then
http://www.example.com/blog/post1
Pro-tip: to be sure, just use lowercase URLs everywhere: in your URL routing, links, and canonical URLs.
Sitemaps and canonical URLs
Sitemaps help search engines index your website. Pages that have canonical URLs pointing to different pages should not be included in your sitemap, because they will not be indexed anyway.
What is the difference between a canonical URL and a redirect?
Redirects and canonical URLs are similar to some degree: both tell the search engine not to index page A, but index page B instead.
There's a big difference though: with a redirect, search engine crawler and visitors cannot access page A. With a canonical, the user and the crawler are not redirected. Users still see page A on their screen.
When to use a redirect?
Use a 301 redirect from page A to page B if you don't want page A to be available. This can be because you've changed the URL, or because you've merged page A and C into page B. In that case, you'll want to forward bots and visitors to page B.
When to use a canonical URL?
Sometimes you want a page to be available, but rather have a different URL indexed. In that case, canonicals are the answer. A good example is pagination: you want the users to be able to navigate through the paginated pages, but you don't want each of these pages to be indexed.
Canonical URLs for non-HTML content
Setting a <link rel="canonical" href="https://www.example.com/test"> is easy on HTML documents. But what if you want to add a canonical URL to a document that visitors can download? There's no way to put that HTML code in a PDF or an Excel file. By using HTTP headers, you can still set a canonical URL on a non-HTML document. A canonical header looks like this:
Link: <https://www.example.com/test.pdf>; rel="canonical"
SiteGuru canonical report
Managing canonical URLs for large websites can be cumbersome. SiteGuru has a canonical URL report that shows you exactly which pages have canonical URLs and alerts you when they point to a redirected page, a page that doesn't work, or a page with a canonical URL.
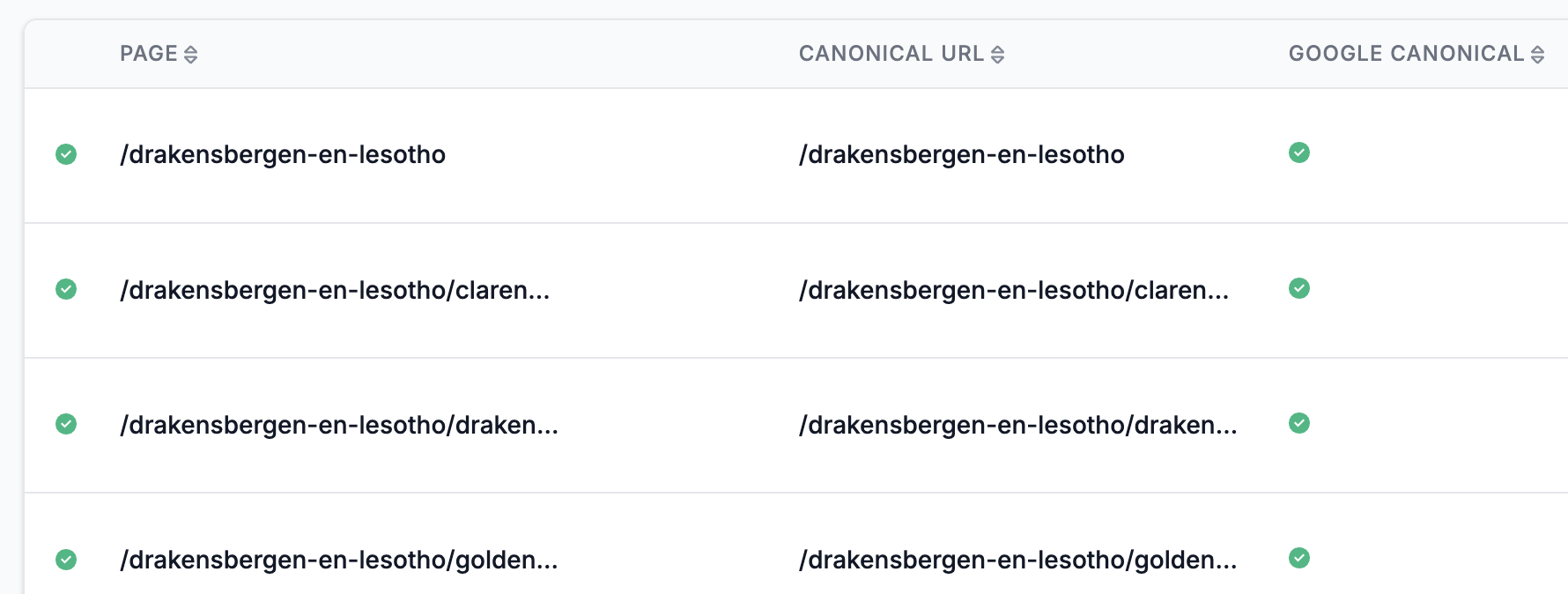
This makes managing and monitoring canonicals a breeze.
